<집계 함수 (그룹 함수)>
-
집계 함수 (Aggregate function): AVG(평균), COUNT(개수), MAX(최대값), MIN(최소값), SUM(합계)
SELECT [그룹열], 그룹 함수 (열 이름)
FROM 테이블명
WHERE 조건
GROUP BY 그룹명
HAVING 그룹 조건
ORDER BY 열이름
-
COUNT: 행의 개수 출력 (null값은 제외됨)
-
employees 테이블의 행의 개수 출력
|
1
2
|
SELECT COUNT(*)
FROM employees;
|
cs |

-
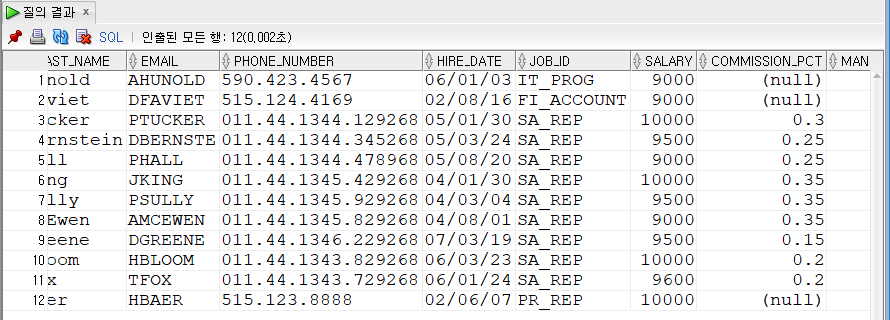
employees 테이블에서 commission_pct의 개수 출력
|
1
2
|
SELECT COUNT(commission_pct)
FROM employees;
|
cs |
-
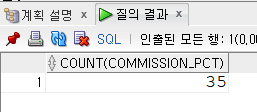
null값도 세고 싶다면?
|
1
2
|
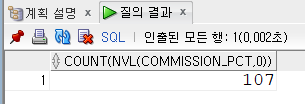
SELECT COUNT(NVL(commission_pct,0))
FROM employees;
|
cs |
-
MAX, MIN: 최대값과 최소값 employees 테이블에서 salary의 가장 큰 값과 작은 값 출력
|
1
2
|
SELECT MAX(salary), MIN(salary)
FROM employees;
|
cs |

-
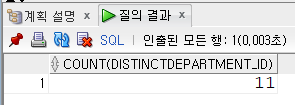
employees 테이블의 부서의 개수 출력
|
1
2
|
SELECT COUNT(DISTINCT department_id)
FROM employees;
|
cs |
-
employees 테이블에서 department_id가 90인 부서의 직원 수 출력
|
1
2
3
|
SELECT COUNT(employee_id)
FROM employees
WHERE department_id = 90;
|
cs |

-
MAX, MIN 함수를 문자열에 적용
|
1
2
|
SELECT MAX(first_name), MIN(first_name)
FROM employees;
|
cs |

-
MAX, MIN 함수를 문자열에 적용 MAX(hire_date)는 가장 최근날짜, MIN(hire_date)는 가장 오래된 날짜.
|
1
2
|
SELECT MAX(hire_date), MIN(hire_date)
FROM employees;
|
cs |

-
SUM, AVG : 합계와 평균 (숫자만 가능)
|
1
2
|
SELECT SUM(salary), AVG(salary)
FROM employees;
|
cs |

-
employees 테이블에서 commission_pct의 평균값을 출력 (널값은 제외)
|
1
2
|
SELECT AVG(commission_pct)
FROM employees;
|
cs |

-
각 부서별로 집계 함수를 내려면 필요한 것이 GROUP BY절
-
employees 테이블에서 department_id별 salary의 평균을 평균급여 이름으로 출력
|
1
2
3
|
SELECT department_id, ROUND(AVG(salary)) 평균급여
FROM employees
GROUP BY department_id;
|
cs |

-
employees 테이블에서 department_id별 salary의 평균을 평균급여 이름으로, salary의 합계를 총급여합계로, department_id를 부서번호로, 부서인원수 출력
|
1
2
3
4
5
6
|
SELECT department_id 부서번호,
ROUND(AVG(salary)) 평균급여,
SUM(salary) 총급여합계,
COUNT(*) 부서인원수
FROM employees
GROUP BY department_id;
|
cs |

-
employees 테이블에서 department_id별, job_id별 salary의 평균을 평균급여 이름으로, salary의 합계를 총급여합계로, department_id를 부서번호로, 부서인원수를 부서별 직업별 인원수로 출력
|
1
2
3
4
5
6
7
|
SELECT department_id 부서번호, job_id 직업번호,
ROUND(AVG(salary)) 평균급여,
SUM(salary) 총급여합계,
COUNT(*) "부서별 직업별 인원수"
FROM employees
GROUP BY department_id, job_id
ORDER BY 부서번호 ASC;
|
cs |

-
HAVING 절: 그룹 함수를 이용한 조건절
|
1
2
3
4
5
|
SELECT department_id 부서번호, SUM(salary) 급여합계
FROM employees
WHERE SUM(salary) > 100000 --그룹함수 사용 에러
GROUP BY department_id
ORDER BY department_id;
|
cs |
-
WHERE절에 salary의 합계가 10000이 넘는 부서번호와 급여합계를 구하면 에러가난다.
-
WHERE절 대신에 HAVING절 사용
|
1
2
3
4
5
|
SELECT department_id 부서번호, SUM(salary) 급여합계
FROM employees
GROUP BY department_id
HAVING SUM(salary) > 100000
ORDER BY department_id;
|
cs |
<집계 함수 예제>
-
employees 테이블에서 부서별 사원수, 최대급여, 최소급여, 급여합계, 평균급여를 급여합계 큰순으로 출력
|
1
2
3
4
5
6
7
|
SELECT department_id, MAX(salary) 최대급여,
MIN(salary) 최소급여,
SUM(salary) 급여합계,
ROUND(AVG(salary)) 평균급여
FROM employees
GROUP BY department_id
ORDER BY 급여합계 DESC;
|
cs |

-
employees 테이블에서 부서별, 직업별(job_id), 상사번호(manager_id)별로 그룹을 지어 salary 합계와 그룹별 직원의 숫자를 출력
|
1
2
3
4
5
6
7
8
|
SELECT department_id 부서번호,
job_id 직업,
manager_id 상사번호,
SUM(salary) 월급합계,
COUNT(*) 직원수
FROM employees
GROUP BY department_id, job_id, manager_id
ORDER BY 부서번호;
|
cs |

-
부서별로 최고 월급을 뽑아서 평균을 내고, 최저 월급 또한 평균을 내어 출력
|
1
2
3
4
|
SELECT ROUND(AVG(MAX(salary))) 부서별최고월급평균,
ROUND(AVG(MIN(salary))) 부서별최저월급평균
FROM employees
GROUP BY department_id;
|
cs |

-
직종별 평균 월급이 $10000을 초과하는 직종에 대해서 job_id와 월급여 합계를 조회. 어카운트 매니저 (AC_MGR)은 제외하고 월 급여 합계로 내림차순 정렬
|
1
2
3
4
5
6
|
SELECT job_id 직종, SUM(salary) 월급여합계
FROM employees
WHERE job_id NOT IN ('AC_MGR')
GROUP BY job_id
HAVING AVG(salary) > 10000
ORDER BY 월급여합계 DESC;
|
cs |

-
부서번호 40을 제외한 부서별 평균 급여가 7000이하인 부서들의 평균 급여를 출력
|
1
2
3
4
5
|
SELECT department_id 부서번호, ROUND(AVG(salary)) 평균급여
FROM employees
WHERE department_id NOT IN ('40')
GROUP BY department_id
HAVING AVG(salary) <= 7000;
|
cs |

-
직종별로 월급의 합계가 13000이상인 직종을 출력. 급여총액으로 내림차순 정렬하고 직종(job_id)에 'REP'들어있는 직종은 제외
|
1
2
3
4
5
6
|
SELECT job_id, SUM(salary) 급여총액
FROM employees
WHERE job_id NOT LIKE '%REP%'
GROUP BY job_id
HAVING SUM(salary) >= 13000
ORDER BY 급여총액 DESC;
|
cs |

'Learning > SQL' 카테고리의 다른 글
| 조인 (JOIN) - 비 동등조인 (0) | 2020.06.17 |
|---|---|
| 조인 (JOIN) - 동등조인 (0) | 2020.06.17 |
| DECODE 함수, CASE 함수 (0) | 2020.06.16 |
| NULL 관련 함수 (0) | 2020.06.16 |
| 변환형 함수 (0) | 2020.06.16 |